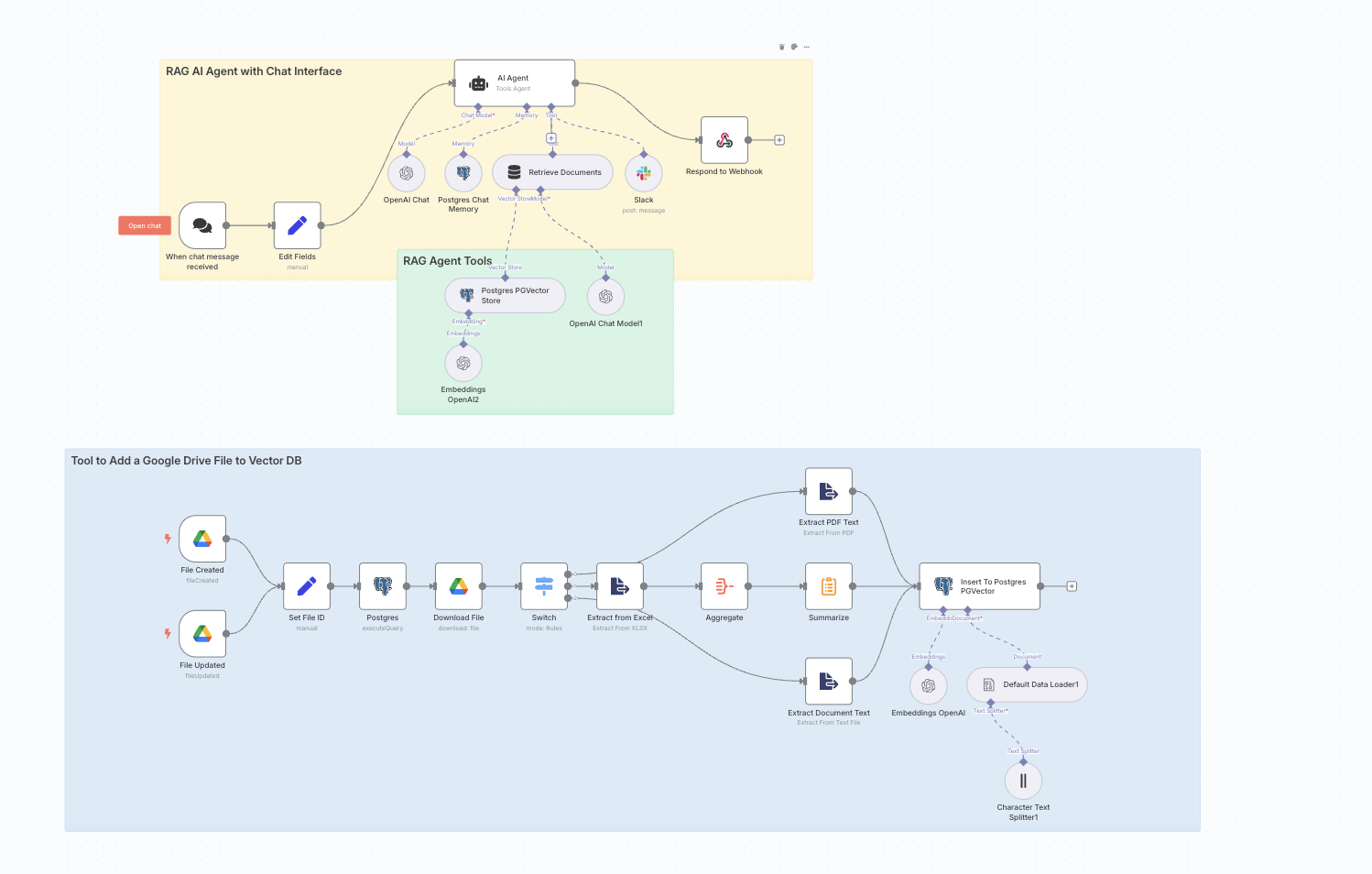
In this case study, I’ll walk through how I built a Retrieval-Augmented Generation (RAG) chatbot workflow using n8n, integrated with OpenAI, Google Drive, Postgres (PGVector), and Slack—entirely in a no-code/low-code environment.
The result is an AI assistant that doesn’t just generate answers—it retrieves relevant context from internal documents and responds intelligently based on it.
The Problem
Many businesses struggle to make sense of the data buried inside PDFs, spreadsheets, and documents. Large language models like ChatGPT are great, but they don’t know your company’s latest SOPs, reports, or internal memos unless you explicitly provide that context.
That’s where RAG comes in: combining retrieval of internal knowledge with generation of coherent responses.
Tools Used
- n8n – Automation orchestrator
- OpenAI API – For text embeddings and chat completion
- Google Drive – Document storage and update trigger
- Postgres with PGVector – Embedding vector database
- Slack – For routing lead messages or contact requests
- LangChain nodes in n8n – To glue the pieces together
Workflow Breakdown
1. Google Drive as the Data Source
The system uses Google Drive Trigger nodes to watch a specific folder. Whenever a file is added or modified, the automation begins.
Supported file types include:
- PDF (application/pdf)
- Google Docs (application/vnd.google-apps.document)
- Excel (.xlsx)
2. File Identification and Cleanup
Each time a file event occurs:
- Metadata (file ID, type) is captured
- Any previous embeddings for that file ID are deleted from the vector database to avoid duplication.
3. File Download and Text Extraction
Depending on the MIME type:
- PDF documents are passed through a PDF text extractor
- Excel files are parsed and concatenated into text
- Google Docs and other formats are converted to plain text
4. Embedding and Storage
The extracted text is then:
- Embedded using OpenAI’s embedding endpoint
- Split into manageable chunks using LangChain’s CharacterTextSplitter
- Inserted into a documents table in Postgres (with PGVector)
Each document is stored along with metadata like file_id, making future retrieval scoped and accurate.
5. Chat Interface with AI Agent
The conversational interface is powered by an AI Agent node:
- Receives chat input via webhook
- Retrieves relevant context from the vector store
- Uses chat memory from previous messages (via Postgres)
- Responds with contextually-aware answers
The prompt used in the agent guides the AI to only answer based on website or document context.
6. Contact Flow via Slack
For leads or contact requests, a custom Slack tool is added:
- The AI asks the user for name, phone, and email
- Collected details are sent to a predefined Slack channel
This replaces the need for a manual form while still capturing structured lead data.
Security and Performance
- The workflow only stores embeddings and metadata, not full raw documents
- Chat history is session-aware and stored in a separate chat_histories table
- Processing is fast, with most documents embedded and stored within seconds
Outcome
This RAG-based architecture allows the assistant to deliver accurate, up-to-date responses without relying solely on static training data. The use of n8n means every component—from ingestion to response—is transparent, editable, and customizable without vendor lock-in.
For teams looking to make their internal knowledge searchable and conversational, this setup offers a practical, modular approach that can be extended as needed—whether to integrate with CRMs, fetch new data types, or route alerts across tools.